Un génome peut être considéré d'un point de vue informatique comme un mot (une suite de lettres) formé à partir de l'alphabet (ensemble de lettres) {A,C,G,T}, où A représente l'adénine, C la cytosine, G la guanine et T la thymine (les 4 nucléotides ou bases).
Un problème actuel en génomique est la détection de répétition de certains motifs (suites de lettres particulières) dans les gènes. Nous allons ici formaliser ce problème sur un alphabet fini quelconque.
On considère un alphabet B comprenant |B| lettres (par exemple B = {A,C,G,T} pour l'ADN). Un mot est une suite de lettres, en particulier il y a le mot vide avec 0 lettre ; la longueur d'un mot x, notée |x|, est le nombre de lettres de celui-ci. On numérote les positions des lettres du mot x de 1 à |x| à partir de la gauche ; par exemple un mot de longueur 5 s'écrit a1a2a3a4a5, où ai est la lettre en position i (i = 1, 2, 3, 4, 5). Un langage est un ensemble F de mots sur l'alphabet B (attention, F ne comprend pas nécessairement, pour une longueur donnée, tous les mots possibles) ; on notera n(F) la taille de F, c.à.d. le nombre de mots qu'il contient.
Soient w et w' deux mots particuliers appelés motifs. Pour un entier i compris entre 0 et imax, le i-motif mi comprend tous les mots formés de w, puis de i lettres quelconques, puis de w' ; on écrira mi = w Ni w', où le symbole N désigne "n'importe quelle lettre". On va mesurer le nombre d'occurences de mi dans un mot x. Par exemple :
B =
{![]() ,
,
![]() ,
,
![]() ,
,
![]() } ,
w =
} ,
w = ![]()
![]() ,
w' =
,
w' = ![]() ,
i = 2,
,
i = 2,
| mi = | |
|
|
|
|
|||||||
| x = | |
|
|
|
|
|
|
|
|
|
|
|
 |
|
|
||||||||||
Les 3 flèches indiquent le début d'un motif mi dans x, aux positions 1, 3 et 8.
Le i-motif mi est de longueur |w| + |w'| + i, donc si dans un mot x il commence en position j, il se terminera en position |w| + |w'| + i + j - 1 ; cette dernière position ne doit pas dépasser la longueur |x| du mot, ainsi
j est compris entre 1 et |x| + 1 - (|w| + |w'| + i) .
Donc le nombre de positions théoriquement possibles pour j vaut |x| + 1 - (|w| + |w'|) pour i = 0, et diminue progressivement quand i augmente, pour atteindre
l(x) = |x| + 1 - (|w| + |w'| + imax) pour i = imax .
Aussi, si on compte le nombre d'occurrences du motif mi dans un mot, à toutes les positions possibles, cela induit un biais en faveur des petites valeurs de i, comme le montre l'exemple suivant :
B =
{![]() ,
,
![]() ,
,
![]() ,
,
![]() } ,
w =
} ,
w = ![]()
![]() ,
w' =
,
w' = ![]() ,
,
| x = | |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| m1 = | |
|
|
|
||||||||||||
| |
|
|
|
|||||||||||||
| m5 = | |
|
|
|
|
|
|
|
||||||||
| |
|
|
||||||||||||||
On compte 4 occurrences de m1, et 3 de
m5 (cfr. les flèches) ; or le mot
x est une répétition périodique du motif
![]()
![]()
![]()
![]() ,
et les deux motifs m1 et m5 se
retrouveraient exactement aux mêmes positions si ce mot
périodique se répétait jusqu'à
l'infini. Pour éliminer ce biais, on ne comptera donc les
occurrences de mi qu'aux positions j
possibles pour i = imax, c.à.d. comprises entre
,
et les deux motifs m1 et m5 se
retrouveraient exactement aux mêmes positions si ce mot
périodique se répétait jusqu'à
l'infini. Pour éliminer ce biais, on ne comptera donc les
occurrences de mi qu'aux positions j
possibles pour i = imax, c.à.d. comprises entre
1 et l(x) = |x| + 1 - (|w| + |w'| + imax) .
On écrira ci(x) le nombre d'occurrences de mi aux positions entre 1 et l(x). Dans l'exemple ci-dessus, en posant imax = 5, on obtient l(x) = 9 et c1(x) = c5(x) = 3. La probabilité d'occurrence de mi dans x sera
oi(x) = ci(x) / l(x) .
Finalement, la probabilité d'occurrence de mi = w Niw' dans le langage F, notée Aw,w'(i,F), sera la moyenne des oi(x) pour tous les n(F) mots xm du langage F :
Aw,w'(i,F) = ( oi(x1) + ... + oi(xn(F)) ) / n(F) .
La fonction définie sur les entiers de 0 à imax, associant à i la valeur Aw,w'(i,F), exprime la probabilité que w' apparaisse i lettres quelconques après w dans un langage F. On l'appellera fonction d'autocorrélation w Ni w'. On s'intéressera au comportement global de cette fonction, notamment la périodicité de ses maxima locaux.
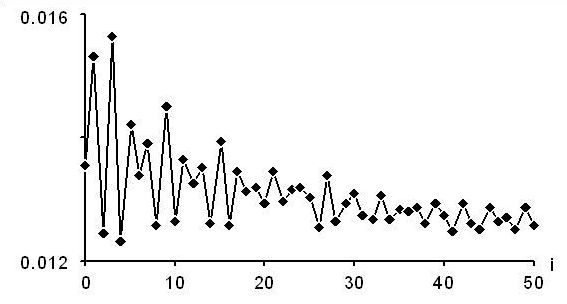
Les 4 bases A, C, G et T de l'ADN sont de deux types : les purines A et G, et les pyrimidines C et T. On a donc l'alphabet réduit à deux lettres {R,Y}, où R = {A,G} désigne une puRine, et Y = {C,T} une pYrimidine. On considère le motif YRY, qui signifie une pyrimidine suivie d'une purine puis d'une pyrimidine, par exemple: CAC, CGT, etc. Des mesures de la fonction d'autocorrélation YRY Ni YRY ont été effectuées sur diverses familles de gènes. Dans les graphiques suivants, l'abcisse est i (variant de 0 à imax = 50) et l'ordonnée est Aw,w'(i,F) pour w = w' = YRY. Le comportement global de la fonction donne des indications sur la structure de la séquence génétique.
Le premier graphique donne la fonction pour les gènes codant les ARN ribosomiques. On note un maximum global pour i = 6, associé au motif YRY N6 YRY.
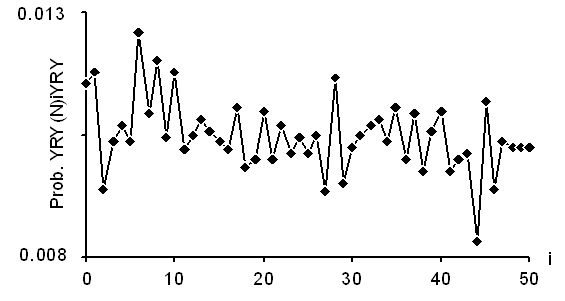
Le graphique suivant donne cette fonction pour les gènes codants des eucaryotes. On remarque un pic de la fonction pour i multiple de 3, et un maximum global pour i =0, ensuite pour i =6. Cette périodicité indique l'existence de motifs du type (RYY)n.
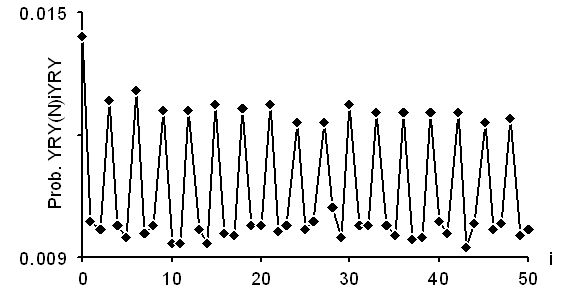
Les deux derniers graphiques donnent cette fonction pour les gènes non-codants des eucaryotes: d'une part les introns, d'autre part les régions 5'. On note que la fonction a un pic pour i impair, indiquant l'existence de motifs du type (RY)n (alternance de bases puriques et pyrimidiques).
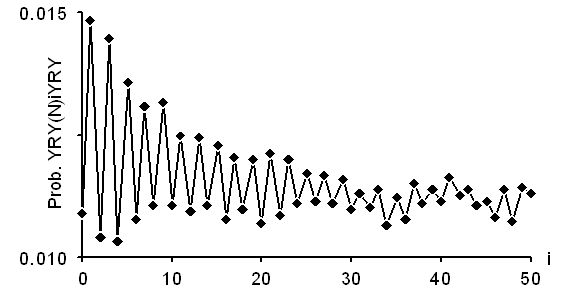
Cette périodicité est vérifiée jusqu'à i = 50 pour les introns (ci-dessus), et jusqu'à i environ 25 pour les régions 5' (ci-dessous).